
Joe Hargreaves is Flinks' Senior Product Manager. He designs tools enabling financial businesses to transform millions of data points into insights-driven decisions.
He's also the main driver behind our passion for pizza.
Data Enrichment: From Chaos to Superpowers
We channel millions of lines of data into a pipeline, eliminate the noise and enable businesses to generate actionable outputs.
This is a data science team’s journey building Attributes, a tool that gives meaning — and impact — to raw transactional data.
At first, there was a big pile of data
Hundreds of companies use our financial data tools to build and power financial products. The engineering and data science teams here at Flinks are hard at work making data accessible through aggregation and meaningful through enrichment.
We already catch a glimpse of what the future of finance looks like for consumers: financial services that delight them with amazing personalized experiences.
It’s easy to agree. Getting there is a whole other story.
As everything becomes connected, data should power processes, products, and experiences. Consumer transactional history, specifically, is readily available and holds a wealth of information about a person’s financial profile and behavior. Yet financial businesses, banks and fintechs alike, are still struggling to extract value from what is often a chaotic mess of data.
There is value in transactional data. So how do we extract it?
Anytime you want to solve a complex problem, you have to start with a first step. Ours had us set foot into a new and exciting territory: building Attributes, a data enrichment tool designed to be flexible and dynamic so it can be applied to all the scenarios where businesses need to understand their customers better.
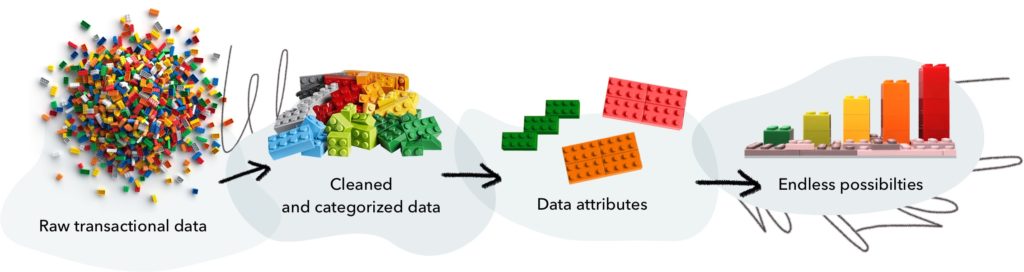
Concretely, we enable them to dig through millions of lines of transaction history and extract complex data attributes that feed their models or enable their experts to make faster, more informed decisions. And frankly, that feels like superpowers.
Getting power from data
Across the industry, categorization of transactional data is mainly used to improve the end-users experience. Personal finance management apps rely heavily on this technology to bring value to their users by giving them visibility and perspective on their transactions. Enhancing transactional data at a granular level, such as adding information about the vendor’s location, makes sense in this context.
The direction we took with Attributes is helping our customers improve their business processes.
Right now, a lot of them rely on manual labor for data manipulation: if a lender wants to know how many NSF fees a customer had in the previous year, someone has to manually comb through bank statements to identify and count them. Even very simple operations are tedious — which means there’s room to innovate and make them faster and more accurate, or even automate them.
To extract value from transactions, we needed to create a tool enabling us to manipulate large swaths of data and summarize them into consumable data attributes. Data attributes are basically custom functions that aggregate data to answer specific questions. Some pretty simple: how many NSF fees did the end user get over the last 12 months? Some very complex: did the end user have any irregular account activity recently?
Each data attribute reveals an aspect of an end user’ financial profile and consumer behavior.
A single data attribute sheds light on a very specific aspect of an end user financial profile — but taken together data attributes create a holistic and accurate view. The goal was to allow our clients to use data attributes much like building blocks, to easily structure the specific data enrichment tool that fits their context. The two fundamental design principles that guided the creation of Attributes are flexibility and dynamism.
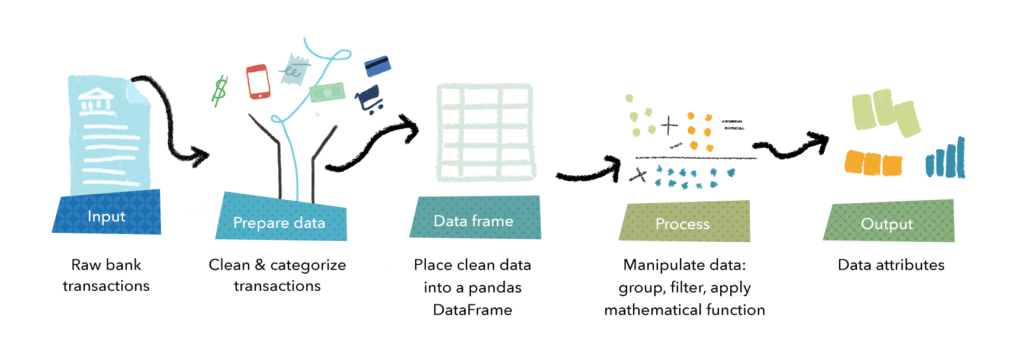
Playing with pandas (DataFrames)
The input to Attributes is raw transactional data. We collect end users’ transactional data through account aggregation. Rows and rows of dates, amounts and descriptions. It’s a messy and noisy dataset that we must clean and categorize.
Quick side note: data categorization is an incredibly fascinating and deep topic that really deserves its own story — so let’s save that for another time. For now, let’s just say that we sort transactions and apply labels that describe them: is it income or expense, what is the source or destination, etc.
We then place that categorized data into a pandas DataFrame. It is a powerful tool allowing us to organize data into rows and columns. Think of a Google spreadsheet built for Python programmers.
The flexibility element of Attributes comes from using pandas DataFrames to structure and manipulate data.

This allows us to build custom functions to interact with the underlying data. Similarly to how data analysts manipulate, transform and summarize data in a spreadsheet, our data science team is able to manipulate, transform and summarize data using pandas DataFrames.
We can build functions to perform complex calculations in a repeatable manner — making the DataFrame a great fit for creating data attributes. And since all of the calculations happen in memory, this process is overall very fast.
Building the building blocks
We originally started with a very basic framework for data manipulations — basic operations such as filtering columns and applying mathematical functions (sum, min, max, count) to generate aggregated outputs. This was a good starting point as it enabled us to get a handle on the nuances of the data, and therefore gave us a solid foundation to build upon.
The dynamic element of Attributes comes from the ability to create increasingly intricate functions to manipulate the data in more subtle ways — and answer very complex questions.
As we began to explore further the needs of our clients, we found out that we needed to employ more complex functions to handle real-world situations. The most natural way for us to tackle this was by adding functions involving the ability to filter multiple columns, group categories together and apply time periodic functions to category distributions.
By adding these functions into our framework, we are able to accurately combine and process millions of lines of transactional data on an aggregated basis to generate data attributes. Even better, we are now able to combine individual data attributes to generate advanced metrics and analyze trends.
Let’s take pizza as an example.
(We are really big fans of pizza.)
Rather than simply focusing on a summation of Pizza Spend, we can now distribute categories around pizza more effectively. Combining Pizza Spend with say, Payroll Income, would return detailed information regarding the relationship between the two. Or maybe a comparison between recent Pizza Spend and Historical Income would be better, answering questions such as:
- If my customer starts earning more money, do they buy more (or less) pizza?
- If my customer had a pay increase two months ago, do they end up spending more money on pizza right now?
What is the right question? It all depends on the specific context of a client. The beauty is that we can build on our current building blocks to face new situations.

Looking forward
So here we are, having taken the first few steps to help financial business give meaning and impact to their data.
Right from the start, our vision has been to make the analysis of transactional data easier.
Up until now, we’ve kept the control over the creation of data attributes to ensure full compatibility with our framework. The next natural step, which our data science team is excited to explore, is to open up that process to our clients and put this functionality directly into their hands.
You might also like

AI: Beware the Solution in Search of a Problem
AI — faster decisions, real-time fraud monitoring, way better UX. But here’s the thing: you need to know exactly what problems you’re trying to solve.

Release Note: Introducing Attributes
Expanding on the capabilities of our core product. This time, we released Attributes — a new insights tool — our Dev docs, custom testing data and more!